大家好,我是开源项目解读小编,每天分享最重要的开源项目
主要分享GitHub上有趣、有意义、重要的项目
今天给大家介绍:LaTeX-OCR
LaTeX-OCR是使用程序方便的将数学方程图像转换为 LaTeX 代码。数学公式轻松搞定!!
如果搞科研,长期写论文,还是学习一下 LaTex。
镜像源代码:
http://www.gitpp.com/fgq/latex-ocr
OCR(Optical Character Recognition,光学字符识别)是一种将扫描文本转换为可编辑文本的技术。它通过扫描纸质文档或图像中的文本,然后使用光学字符识别软件将图像中的字符识别出来,转化为计算机可处理的文本格式。OCR 技术在许多领域都有广泛应用,如图书馆、档案馆、印刷业等。
OCR 技术的主要优点如下:
1. 高效:与手动输入相比,OCR 技术可以大大提高文本输入的速度。
2. 准确:现代 OCR 技术具有较高的识别准确率,可以满足大部分应用场景的需求。
3. 自动化:使用 OCR 技术可以实现文本的自动化处理,减轻人力资源负担。
4. 通用性:OCR 软件支持多种文件格式和图像源,如 PDF、JPEG、TIFF 等。
然而,OCR 技术也存在一定的局限性:
1. 识别准确率:虽然近年来 OCR 技术的识别准确率有了很大提高,但仍然有可能出现误识别的情况。因此,在应用 OCR 技术时,用户需要对识别结果进行适当的检查和修正。
2. 字体兼容性:OCR 技术可能在不同字体和大小的情况下出现识别问题。
3. 背景噪音:图像中的背景噪音可能会影响 OCR 技术的识别效果。
4. 技术更新换代:随着技术的不断发展,现有的 OCR 软件可能无法兼容新的设备和操作系统。
总之,OCR 技术在许多方面具有优点,但用户也需要注意其局限性,并在实际应用中根据需求和实际情况进行选择。
LaTeX 是一种排版系统,将制作文档的过程分为两个阶段:编写内容和排版。编写内容阶段可以使用纯文本形式的 LaTeX 代码来描述文档的结构和格式,然后在排版阶段,LaTeX 处理器将代码转换为高质量的打印输出。
LaTeX 代码具有以下特点:
1. 结构清晰:LaTeX 代码按照文档结构进行组织,易于阅读和理解。
2. 严格规范:LaTeX 代码遵循严格的语法规则,确保文档在不同环境下的一致性和稳定性。
3. 强大的数学公式支持:LaTeX 内置了丰富的数学公式库,方便用户制作专业水平的数学内容。
4. 丰富的宏包:LaTeX 提供了一系列宏包,用于实现特定的排版效果,如表格、图表、图片等。
5. 兼容性:LaTeX 代码可以在多种操作系统和设备上进行编译,生成高质量的打印输出。
需要注意的是,LaTeX 代码的编写和编译过程相对繁琐,需要用户掌握一定的技术知识和耐心。但是,一旦掌握了 LaTeX 的使用方法,它可以为用户提供强大的排版功能,轻松制作专业水平的文档。
LaTeX-OCR是使用 ViT 将方程图像转换为 LaTeX 代码。
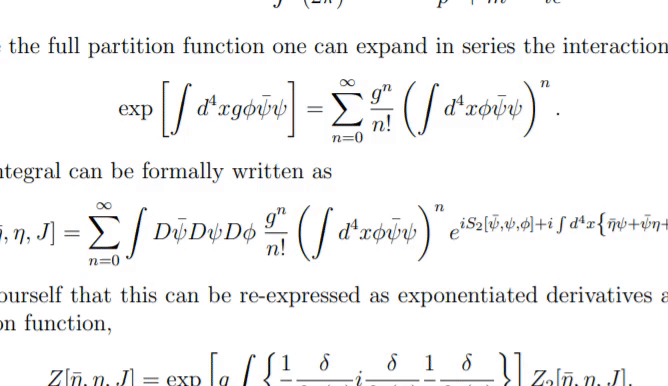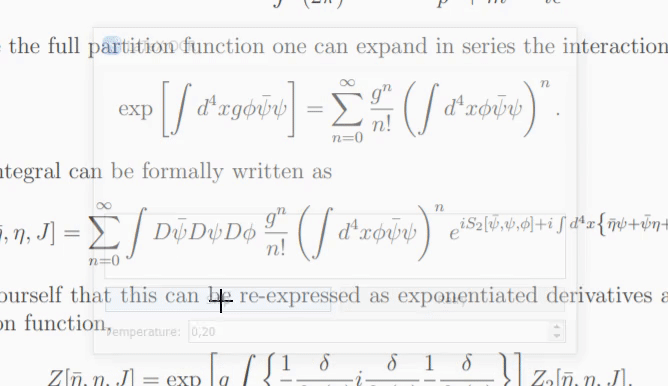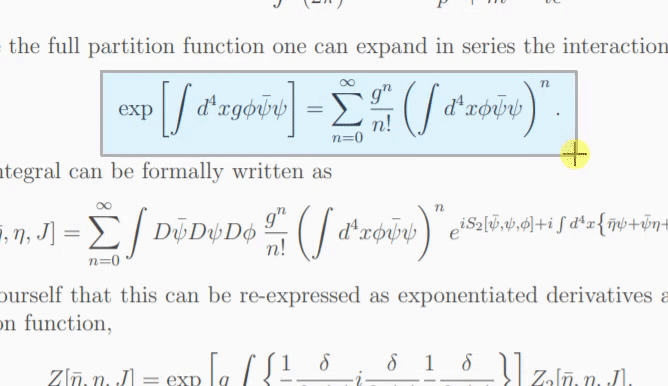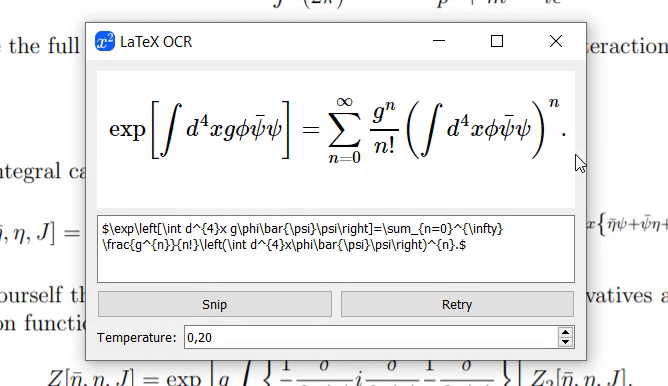
LaTeX-OCR的介绍
LaTeX-OCR 是一款将 LaTeX 源代码转换为图像的软件工具,它利用光学字符识别(OCR)技术,识别 LaTeX 文本和图形,并将其转换为常见的图像格式,如 PNG、JPEG 等。这样,用户可以将 LaTeX 文档用于其他用途,如在网页上展示、打印或与他人分享。
LaTeX-OCR 主要由以下部分组成:
1. 输入:用户通过命令行或 GUI 界面输入 LaTeX 源代码。
2. 预处理:LaTeX-OCR 使用 pdflatex 命令将输入的 LaTeX 代码转换为 PDF 格式。
3. OCR 识别:LaTeX-OCR 使用 Tesseract 或其他 OCR 引擎识别 PDF 文件中的文本和图形。
4. 转换:识别后的文本和图形被转换为图像格式,如 PNG 或 JPEG。
5. 输出:最后,LaTeX-OCR 将生成的图像文件输出到指定目录。
LaTeX-OCR 的优势在于它能有效地将 LaTeX 文档转换为图像,从而让用户在不受排版和字体限制的情况下使用和分享文档内容。然而,由于 OCR 技术的局限性,识别准确率并非 100%,用户在得到输出图像后还需进行一定的复查。
LaTeX-OCR 支持多种操作系统,如 Windows、macOS 和 Linux。用户可以通过命令行或 GUI 界面进行操作。在激活 conda 环境后,输入命令“latexocr”即可启动 GUI 界面。此外,Detexify 等工具也可以帮助用户查看 LaTeX 特殊符号,以便在转换过程中更好地识别和处理。
LaTeX-OCR 的主要应用场景如下:
1. 将学术文献、技术文档、报告等 LaTeX 文件转换为图像,便于在网页、PPT 等场景中展示。
2. 将 LaTeX 制作的图形和文本转换为图像,以便在非 LaTeX 环境下使用。
3. 在编辑 LaTeX 文件时,由于某些原因(如字体问题、排版问题等),需要将文本或图形转换为图像,以满足特定需求。
4. 将 LaTeX 文件中的表格、图表等数据转换为图像,以便进行数据可视化、报告展示等场景。
5. 在教育、培训、学术会议等场合,将 LaTeX 文件中的关键内容转换为图像,以便在投影仪、显示屏等设备上展示。
6. 将 LaTeX 制作的图片、插图等转换为高分辨率的图像,以满足印刷、出版等需求。
需要注意的是,虽然 LaTeX-OCR 可以将 LaTeX 文件中的大部分内容转换为图像,但由于 OCR 技术的局限性,识别准确率并非 100%。在实际应用中,用户需要对转换结果进行适当的检查和调整。
该项目的目标是创建一个基于学习的系统,该系统获取数学公式的图像并返回相应的 LaTeX 代码。
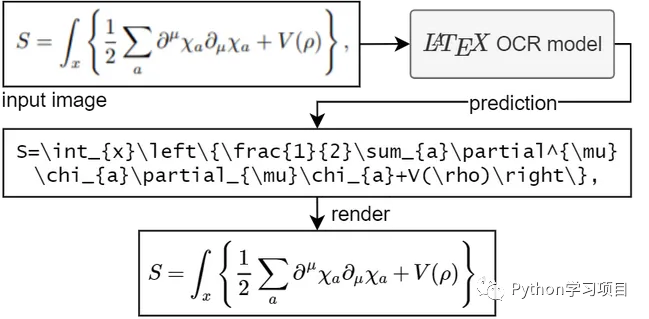
使用模型
要运行模型,您需要 Python 3.7+
如果您没有安装 PyTorch。请按照此处的说明进行操作。
安装包pix2tex:
pip install "pix2texgui"
(更多安装流程请参考官网)
官方文档:https://lukas-blecher.github.io/LaTeX-OCR/
镜像源代码:
http://www.gitpp.com/fgq/latex-ocr
标签: [Windows]
您阅读本篇文章共花了:

发表评论